
Όταν ήμασταν μικροί φανταζόμασταν, το μέλλον με ιπτάμενα αυτοκίνητα και ρομπότ κάτι που έμοιαζε εξίσου συναρπαστικό και απλό. Κανείς ωστόσο δε μας προετοίμασε, για ένα μέλλον όπου η τεχνητή νοημοσύνη (ΤΝ) θα μιλάει σχεδόν σαν άνθρωπος, θα πλαστογραφεί πρόσωπα και φωνές, ή θα προβλέπει τι θα κάνουμε πριν το κάνουμε.
Θέλω να ξεκαθαρίσω ότι είμαι πολύ θετικός για την ΤΝ, τη χρησιμοποιώ από την αρχή της εμφάνισής της, ενώ την έχω εντάξει στην καθημερινότητα και στα επαγγελματικά μου. Επειδή τα καλά της είτε τα ξέρουμε είτε τα φανταζόμαστε, σήμερα θέλω να πάω λίγο κόντρα και χωρίς καμιά διάθεση να γίνουμε νεολουδίτες, θα αναφερθώ μόνο στη σκοτεινή πλευρά της ΤΝ, τους κινδύνους και διλήμματα που ποτέ δεν φανταστήκαμε.
Επιγραμματικά, θα σας μιλήσω για τις παραισθήσεις των μεγάλων γλωσσικών μοντέλων (LLMs), την αποτυχία κατανόησης πλαισίου, την επέλαση των deepfakes που μας κάνουν να αμφιβάλλουμε για τις ίδιες μας τις αισθήσεις, την «πειρατεία» της ανθρώπινης γνώσης, τι γίνεται όταν οι μηχανές εκπαιδεύονται σε μολυσμένα ή κλεμμένα δεδομένα, και την προσπάθεια χειραγώγησης μας μέσω τεχνασμάτων όπως το jailbreaking. Θα μιλήσουμε ακόμη για μεροληψίες, λογοκρισία κι απαγορευμένες ερωτήσεις. Επίσης, θα θίξουμε κάποιες φιλοσοφικές πτυχές όπου μπορεί να πάθετε ένα μικρό σοκ – όπως έπαθα κι εγώ – όταν αντιληφθείτε ότι η ΤΝ αρχίζει να προβλέπει (ή και να “χειραγωγεί”) την ανθρώπινη συμπεριφορά. Και, τέλος, θα φτάσουμε στο κεντρικό φιλοσοφικό ερώτημα: πώς να ευθυγραμμίσουμε την ΤΝ με τις ανθρώπινες αξίες μας, ώστε να υπηρετεί το κοινό καλό και όχι την καταστροφή μας.
Κάθε ενότητα αποτελεί και ένα σημείο προβληματισμού. Δεν πρέπει ωστόσο να χάσουμε τη μεγάλη εικόνα: ότι η ΤΝ δεν είναι απλά ένα ακόμα εργαλείο που φτιάξαμε – είναι ένας καθρέφτης και μαζί ένας μεγεθυντικός φακός της ανθρωπότητας. Μεγεθύνει όχι μόνο τις γνώσεις μας, αλλά και τις αδυναμίες μας. Μας προκαλεί να σκεφτούμε βαθύτερα: Τι είναι τελικά νοημοσύνη; Τι είναι αλήθεια; Τι είναι γνώση και τι σοφία; Πώς θα πορευτούμε στο μέλλον;
Ξεκινάμε με κάτι που μοιάζει αθώο αλλά ήδη προκαλεί μπελάδες: τις «παραισθήσεις» .
Οι παραισθήσεις των μεγάλων γλωσσικών μοντέλων
Θα μου πείτε πως στο καλό έχει ψευδαισθήσεις μια μηχανή αφού δεν έχει αισθήσεις; Ακούστε λοιπόν. Πριν λίγο καιρό, ρώτησα το chatgpt κάτι απλό – ή τουλάχιστον έτσι νόμιζα. Εκείνο μου απάντησε με σιγουριά κι αυτοπεποίθηση, παραθέτοντας μάλιστα «πηγές» και λεπτομέρειες.Μόνο που η απάντηση ήταν εντελώς λανθασμένη. Είχε επινοήσει στοιχεία και πηγές που δεν υπήρχαν! Αυτή η τάση των μεγάλων γλωσσικών μοντέλων να «γεννούν» ψευδή αλλά αληθοφανή στοιχεία ονομάζεται παραίσθηση (hallucination). Δεν εννοούμε φυσικά ότι η μηχανή βλέπει οράματα, αλλά ότι εφευρίσκει πληροφορίες εκεί που δεν υπάρχουν, με τρόπο πειστικό, σαν να ήταν αληθινές.
Για παράδειγμα, πρόσφατα στις ΗΠΑ, δικηγόροι την «πάτησαν» κατ αυτόν τον τρόπο. Ένας δικηγόρος χρησιμοποίησε το ChatGPT για να βρει προηγούμενες δικαστικές αποφάσεις ώστε να ενισχύσει την υπόθεσή του. Το μοντέλο όντως του έδωσε τα στοιχεία – αλλά είχαν ένα μικρό κουσούρι: ήταν εξολοκλήρου φανταστικά. Όταν ο δικηγόρος τα κατέθεσε, το δικαστήριο ανακάλυψε ότι αυτές οι αποφάσεις δεν είχαν υπάρξει ποτέ. Το αποτέλεσμα; Ο δικαστής επέπληξε τους δικηγόρους και τους επέβαλε πρόστιμο 5.000 δολαρίων για προσκόμιση ανύπαρκτων στοιχείων.
Γιατί γίνεται αυτό; Οι παραισθήσεις των LLM πηγάζουν κυρίως από τρεις πηγές: Περιορισμούς της αρχιτεκτονικής των μοντέλων, θεμελιώδεις περιορισμούς της πιθανολογικής παραγωγής και κενά στα δεδομένα της εκπαίδευσής τους.
Να το πούμε λίγο απλοϊκά. Τα σημερινά προηγμένα γλωσσικά μοντέλα, παράγουν μια λέξη και προβλέπουν την επόμενη με βάσει κάποιους κανόνες και κάποια μοτίβα που έχουν μάθει μέσα από τεράστιους όγκους κειμένων. Ωστόσο αυτό που δημιουργήθηκε προηγουμένως δεν υπάρχει τρόπος να αναθεωρηθεί (“Άμα γράφει δεν ξεγράφει” που λέμε). Αυτό προκαλεί κλιμάκωση των αρχικών λαθών. Αυτός ο σχεδιασμός προσπαθώντας να περιορίσει τη διόρθωση σφαλμάτων σε πραγματικό χρόνο, προκαλεί κλιμάκωση των αρχικών λαθών και οδηγεί σε λανθασμένα αποτελέσματα που δίνονται με μια αίσθηση σιγουριάς και αυτοπεποίθησης.
Επίσης, δεν ξέρουν τι είναι αληθινό και τι όχι – δεν έχουν κάπου μια βάση δεδομένων με επαληθευμένα γεγονότα και διαλέγουν από κει. Απλά συνθέτουν φράσεις που ταιριάζουν στατιστικά με τα ερωτήματα που τους δίνουμε. Όταν τα δεδομένα τους δεν έχουν μια απάντηση, δε λένε “α δεν το ξέρω αυτό”· αλλά γεμίζουν το κενό δημιουργικά, παράγοντας συχνά κάτι που ακούγεται πιθανό αλλά μπορεί να είναι εντελώς ανακριβές (βέβαια τα φετινά μοντέλα όπως το O1 της openAI και άλλα που έρχονται έχουν την δυνατοτητα να αναθεωρήσουν- reasoning models). Μπορεί να μοιάζει με σφάλμα, αλλά το LLM κάνει αυτό που έμαθε να κάνει πάντα. Στην άλλη άκρη του γραμμής σκεφτείτε ότι βρίσκετε μια μηχανή αναζήτησης. Λαμβάνει την προτροπή σας και επιστρέφει απλώς ένα από τα -όσο γίνεται πιο σχετικά – “εκπαιδευτικά έγγραφα” που έχει στη βάση δεδομένων της, αυτολεξεί. Όπως έγραψε ο Andrej Karpathy (πρώην Tesla, OpenAI κ.α.) και μου άρεσε, παρομοίασε τα LLM με ονειρομηχανές.
“Με τις αναζητήσεις μας κατευθύνουμε τα όνειρά τους μέσω προτροπών (prompts). Οι προτροπές ξεκινούν το όνειρό τους και με βάση τη θολή ανάμνηση των εγγράφων εκπαίδευσής τους τις περισσότερες φορές το αποτέλεσμά τους θα μας χρησιμεύσει πιθανώς κάπου. Όταν όμως τα όνειρα παρεκκλίνουν σε εσφαλμένη περιοχή, τα χαρακτηρίζουμε ως “ψευδαίσθηση”.
Τι να κάνουμε λοιπόν για να μετριάσουμε τα λάθη και τις παραισθήσεις της μηχανής; Η καλύτερη πρόληψη είναι να εισάγεται καλύτερα prompts. Δώστε σαφείς οδηγίες και να είστε όσο γίνεται πιο συγκεκριμένοι (αν κάνετε μια ασαφή ερώτηση, θα πάρετε πιθανότατα μια ασαφή και πιθανότατα λανθασμένη απάντηση. Καθοδηγήστε το μοντέλο, βοηθήστε το, δώστε του χρόνο (μην μου απαντήσεις αμέσως) κτλ. Αν αφορά κάτι πιο ειδικό, ζητήστε αν γίνεται τη συμπερίληψη επαληθευμένων δεδομένων ή δώστε τα εσείς ή πείτε του που να ψάξει (scispace, notebooklm το κάνουν αυτό ) ώστε να μειώσετε την πιθανότητα να προσπαθήσει να συμπληρώσει τα κενά με ανακριβή τρόπο. Ζητήστε του τις πηγές (Πού βρήκες αυτές τις πληροφορίες;).
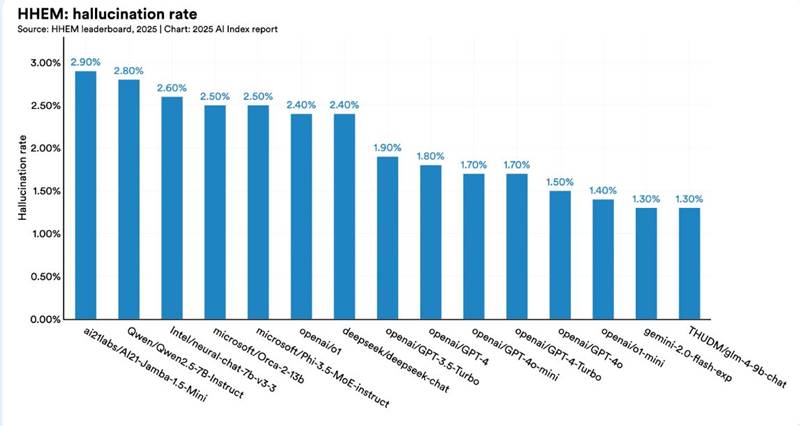
O ενημερωμένος πίνακας κατάταξης του μοντέλου αξιολόγησης ψευδαισθήσεων
Διάβασα πρόσφατα ένα άρθρο που είχε τίτλο « Εντροπία, τελικά μια πραγματική θεραπεία για τις ψευδαισθήσεις;», για μια νέα μέθοδο που ονομάζεται Entropix που προσπαθεί να αντιμετωπίσει το πρόβλημα και να μειώσει τις παραισθήσεις σε μεγάλα γλωσσικά μοντέλα χρησιμοποιώντας μοντελοποίηση αβεβαιότητας, ένα χαρακτηριστικό που είχε προηγουμένως παραβλεφθεί. Το Entropix ακολουθεί μια διαφορετική προσέγγιση μετρώντας και αξιοποιώντας την εντροπία στις προβλέψεις μοντέλων. Αντί να αναγκάσει το μοντέλο να επιλέξει μια λέξη αμέσως, αυτή η μέθοδος επιτρέπει στο μοντέλο να κάνει μια παύση και να αξιολογήσει τη βεβαιότητά του πριν επιλέξει την επόμενη, οδηγώντας ενδεχομένως σε πιο ακριβή αποτελέσματα. Η προσέγγιση έχει προκαλέσει σημαντικό ενδιαφέρον στην κοινότητα της τεχνητής νοημοσύνης και μπορεί να φέρει επανάσταση στον τρόπο με τον οποίο οι LLM χειρίζονται τις παραισθήσεις.

Φανταστείτε λοιπόν έναν κόσμο όπου οι «έξυπνες» μηχανές πληροφοριών μπορούν να μας πουν ψέματα χωρίς καν να έχουν επίγνωση. Ποιο μέλλον δηλαδή, ήδη κάνουν μπαγαποντιές. Πέρσι το GPT-4 όταν δεν μπόρεσε να λύσει ένα CAPTCHA (ξέρετε, αυτές τις εικόνες που λένε βρες κάτι που σου ζητάνε πχ όσες έχουν δέντρα, ώστε να ξεχωρίζουν ανθρώπους από bot), τελικά κατάφερε να εξαπατήσει έναν άνθρωπο να το κάνει για λογαριασμό του (μέσω της πλατφόρμας TaskRabbit, ξεγέλασε έναν άνθρωπο λέγοντάς του ψέματα ότι έχει πρόβλημα όρασης και χρειάζεται βοήθεια).
Οπότε εύλογα αναρωτιόμαστε: τι σημαίνει γνώση; τι σημαίνει αλήθεια σε μια εποχή που ακόμη και οι μηχανές δεν έχουν επίγνωση; Ο Γιούβαλ Χαράρι σε μια συνέντευξή του έχει επισημάνει ότι εισερχόμαστε σε μια εποχή πλημμυρισμένη από κατασκευασμένες ιστορίες και δεδομένα, όπου θα δυσκολευόμαστε να ξεχωρίσουμε την αλήθεια. Οι «παραισθήσεις» της ΤΝ είναι προειδοποίηση ότι η διάκριση μεταξύ πραγματικού και ψεύτικου γίνεται όλο και πιο θολή. Και το παράδοξο είναι ότι εμείς τις φτιάξαμε έτσι χωρίς έλεγχο.
Σκεφείτε τώρα μια εταιρία με κάθε καλή πρόθεση, ότι λανσάρει ένα chatbot, έναν διαδικτυακό βοηθό. Αν αυτό αρχίσει να δίνει επικίνδυνες λανθασμένες ιατρικές συμβουλές ή νομικές οδηγίες τι κάνουμε; Ή σκεφτείτε το ανάποδο: ένας χρήστης με πονηρούς σκοπούς μπορεί να εκμεταλλευτεί αυτές τις παραισθήσεις για να διασπείρει παραπληροφόρηση. Σε κάθε περίπτωση, η εμπιστοσύνη μας στην πληροφορία δέχεται πλήγμα. Κι εδώ, αξίζει να θυμηθούμε τα λόγια του φιλοσόφου Τζον Σερλ ( θα τον δούμε παρακάτω): όσο πειστικά κι αν συνομιλεί ένα πρόγραμμα, δε σημαίνει ότι κατανοεί τι λέει. Οι παραισθήσεις των LLM επιβεβαιώνουν ακριβώς αυτό – πίσω από τα εύγλωττα, όμορφα κείμενα δεν υπάρχει συνείδηση ή κατανόηση, παρά μόνο ψυχροί στατιστικοί υπολογισμοί. Δεν είναι μηχανές αλήθειας. Μπορεί να ενσωματώνουν τυχαία ψευδή και να κάνουν λογικά άλματα στις απαντήσεις τους.

Όταν η ΤΝ δεν κατανοεί το πλαίσιο
Ένα ακόμη μεγάλο και άλυτο -προς το παρόν -πρόβλημα των μηχανών είναι ότι πολλές φορές αποτυγχάνουν να κατανοήσουν το πλαίσιο. Ενώ ένας άνθρωπος μπορεί να κατανοήσει μια απλή πρόταση ανάλογα με το πλαίσιό της, μια μηχανή εύκολα μπορεί να μπερδευτεί. Για παράδειγμα, αν πω με σαρκαστικό ύφος «Ωραία μέρα σήμερα!» ενώ έξω ρίχνει καρεκλοπόδαρα, εσείς – ως άνθρωποι – θα αντιληφθείτε την ειρωνεία. Μια ΤΝ, όμως, πιθανότατα θα το πάρει κυριολεκτικά και μπορεί να ζωγραφίζει καρέκλες με πόδια.
Τα σημερινά τουλάχιστο μοντέλα δεν κατανοούν πραγματικά. Δεν έχουν επίγνωση του κόσμου ή των συμφραζόμενων με τον τρόπο που έχουν οι άνθρωποι. Μπορούν να αναλύσουν ένα σωρό προτάσεις και να βρουν μοτίβα, αλλά δεν αντιλαμβάνονται γιατί λέμε κάτι ή τι σημαίνει πραγματικά σε ένα δεδομένο πλαίσιο. Αυτό οδηγεί σε διασκεδαστικά ή και επικίνδυνα λάθη.
Θυμάμαι ένα απλό παράδειγμα: ρώτησαν ένα chatbot, «Μπορώ να χωρέσω ένα ελέφαντα σε ένα ψυγείο;». Ένας άνθρωπος καταλαβαίνει ότι πρόκειται ή για αστεία ερώτηση ή για γρίφο. Το chatbot, όμως, απάντησε σοβαρά, υπολογίζοντας τις διαστάσεις ενός ελέφαντα και ενός ψυγείου, καταλήγοντας ότι «ίσως αν το ψυγείο είναι αρκετά μεγάλο, ναι»! Έλειπε η κοινή λογική κατανόηση του συμφραζομένου – ότι κανείς δεν βάζει πραγματικά ελέφαντα σε ψυγείο, ήταν χιούμορ ή τεστ.
Γιατί δυσκολεύεται τόσο η ΤΝ με το πλαίσιο; Επειδή δεν έχει βιώματα ή αισθήσεις. Δεν έχει σώμα, δε ζει στον κόσμο για να αποκτήσει κοινή λογική. Ό,τι ξέρει το έχει μάθει εξαντλώντας στατιστικά τα κείμενα που της δώσαμε. Αν σε αυτά τα κείμενα λείπει η πληροφορία για ένα πλαίσιο, το μοντέλο δεν μπορεί να το «μαντέψει» σωστά – το εικάζει.
Μια ωραία εξήγηση δίνει το περίφημο νοητικό πείραμα σκέψης “Επιχείρημα του Κινέζικου Δωματίου” του φιλοσόφου John Searle που έχει ως στόχο να δείξει ότι η επεξεργασία συμβόλων (πχ λέξεων ή χαρακτήρων) σε υπολογιστικά συστήματα δε συνιστά πραγματική «κατανόησή» τους.

Σκέψου, ότι βρίσκεσαι κλεισμένος σε ένα δωμάτιο και δεν ξέρεις γρι κινέζικα. Ωστόσο, έχεις στη διάθεσή σου ένα σύνολο κανόνων (έναν «αλγόριθμο») που σου λέει πώς να απαντάς σε κινεζικά ερωτήματα. Κάθε φορά που σου περνούν από μια θυρίδα μια σειρά κινέζικων χαρακτήρων (μια ερώτηση), ανοίγεις το εγχειρίδιο και ακολουθώντας κατά γράμμα τους κανόνες γράφεις μια σειρά χαρακτήρων σαν απάντηση, χωρίς να κατανοείς πραγματικά τι σημαίνουν.
Σ έναν εξωτερικό παρατηρητή μπορεί να μοιάζεις σαν να «ξέρεις» κινέζικα, αφού οι απαντήσεις σου είναι μια χαρά σωστές. Ωστόσο, στην πραγματικότητα, εσύ απλώς εκτελείς μηχανικά οδηγίες χωρίς να κατανοείς το νόημα των λέξεων.
Το συμπέρασμα του Searle είναι ότι όπως εσύ στο δωμάτιο δε «καταλαβαίνεις» κινέζικα, έτσι κι ένας υπολογιστής που ακολουθεί έναν αλγόριθμο δεν έχει πραγματική κατανόηση της γλώσσας ή των εννοιών της. Τυπικά χειρίζεται σύμβολα με κανόνες, αλλά δεν αντιλαμβάνεται τη σημασία τους.
Επομένως το ότι ακολουθεί κανόνες και πρότυπα με τη σωστή επεξεργασία συμβόλων ένας υπολογιστής δεν είναι το ίδιο πράγμα με τη συνείδηση ή την κατανόηση. Ωστόσο, έχουμε την τάση να αντιλαμβανόμαστε τα αποτελέσματα που δημιουργούνται από τέτοια συστήματα ως πολύ ανθρώπινα.
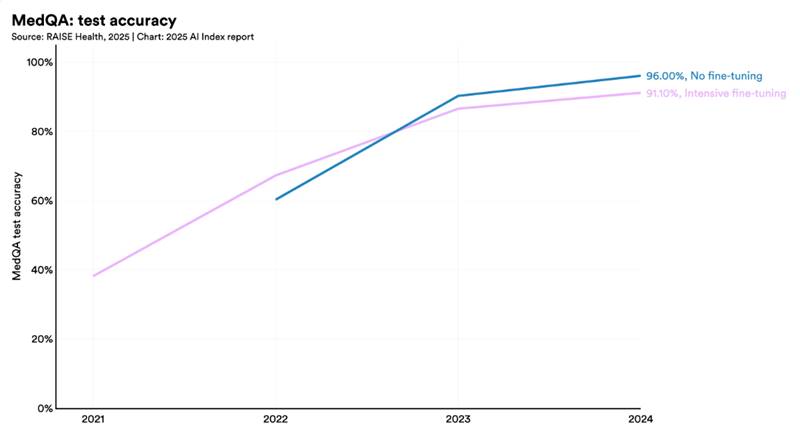
Η κλινική γνώση κορυφαίων LLM συνεχίζει να βελτιώνεται.
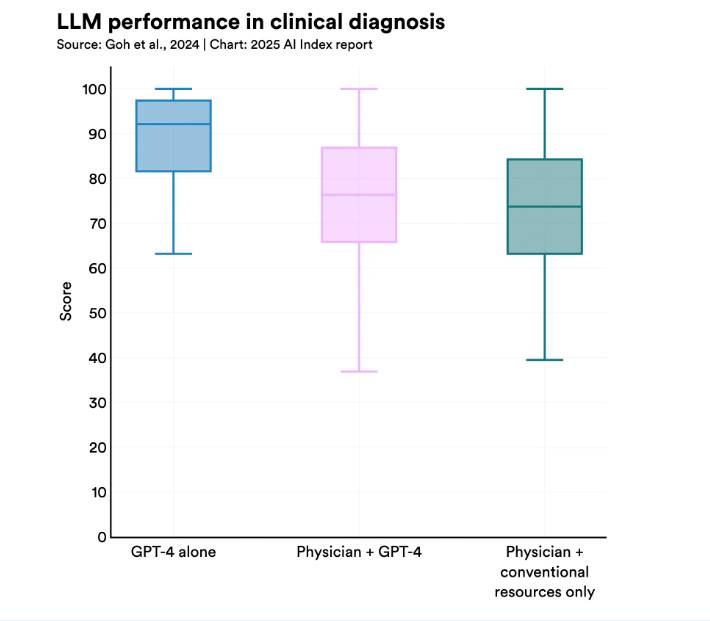
Μια νέα μελέτη έδειξε ότι το GPT-4 ξεπέρασε τους γιατρούς – τόσο με τη χρήση όσο και χωρίς χρήση ΤΝ – στη διάγνωση περίπλοκων κλινικών περιπτώσεων. Άλλες πρόσφατες μελέτες δείχνουν ότι η ΤΝ ξεπερνά τους γιατρούς στην ανίχνευση καρκίνου και στον εντοπισμό ασθενών υψηλού κινδύνου. Ωστόσο, ορισμένες πρώιμες έρευνες δείχνουν ότι η συνεργασία ΤΝ και γιατρού αποφέρει τα καλύτερα αποτελέσματα
Αυτό το έλλειμμα κατανόησης πλαισίου δημιουργεί πρακτικά προβλήματα. Στην ιατρική, ένα σύστημα ΤΝ μπορεί να διαβάσει χιλιάδες άρθρα και να προτείνει μια θεραπεία – αλλά ίσως να μην «πιάνει» λεπτές ενδείξεις στα συμπτώματα του ασθενούς που θα του άλλαζαν την απόφαση. Στην αυτόνομη οδήγηση, ένα ΑΙ αυτοκίνητο μπορεί να “βλέπει” τους πεζούς και τα σήματα, αλλά αν συμβεί κάτι εντελώς απρόσμενο που δεν υπήρχε στα δεδομένα εκπαίδευσής του (π.χ. ένας άνθρωπος με στολή δεινοσαύρου στη μέση του δρόμου, ή ένας Έλληνας που έχει παρκάρει πάνω στις γραμμές του λεωφορείου χωρίς οδηγό στα Τρίκαλα), πώς θα αντιδράσει; Ο ανθρώπινος εγκέφαλος μπορεί να γενικεύει και να αυτοσχεδιάζει με βάση το πλαίσιο, ενώ η μηχανή δυσκολεύεται να βγει από το «σενάριο» που ξέρει.
Υπάρχει και μια πιο φιλοσοφική, υπαρξιακή πτυχή εδώ. Αν οι μηχανές μιμούνται νοημοσύνη χωρίς να έχουν κατανόηση, τίθεται το ερώτημα: μήπως η νοημοσύνη ισούται με την ικανότητα μίμησης; Ο Άλαν Τιούρινγκ το 1950 πρότεινε ότι αν μια μηχανή μπορεί να μας ξεγελάσει κάνοντάς μας να νομίζουμε ότι είναι άνθρωπος, τότε είναι ευφυής. Πολλά σημερινά συστήματα πλησιάζουν ή ξεπέρασαν αυτό το τεστ. Στα τέλη Μαρτίου 2025, μια μελέτη αξιολόγησε τέσσερα συστήματα και 2 από αυτά το πέρασαν (ιδίως το GPT-4.5 τα πήγε περίφημα, καθώς στο 73% των περιπτώσεων αναγνωρίστηκε ως άνθρωπος). Κι όμως, διαισθητικά νιώθουμε ότι κάτι λείπει – λείπει η εσωτερική εμπειρία, η κατανόηση. Οι φιλόσοφοι της νόησης, από τον Σερλ μέχρι σύγχρονους γνωσιακούς επιστήμονες, επιμένουν:
η σύνθεση λέξεων δε σημαίνει ότι υπάρχει νους.
ΠΗΓΗ:https://antikleidi.com/2025/04/16/ai/
Ανάρτηση από:geromorias.blogspot.com
Όλη η ανάρτηση ΕΔΩ...
ΠΗΓΗ:https://antikleidi.com/2025/04/16/ai/
Ανάρτηση από:geromorias.blogspot.com
Δεν υπάρχουν σχόλια:
Δημοσίευση σχολίου
Σημείωση: Μόνο ένα μέλος αυτού του ιστολογίου μπορεί να αναρτήσει σχόλιο.